[tech] Technical Primer on MCP

Model Content Protocol is a new open protocol that enables the building of AI applications. Releasing a standard is easy, but getting adoption is hard. MCP has potentially crossed this chasm and entered into the technical zeitgeist with articles at arstechnica.
Adoption of the standard has been rapid.
Anthropic released MCP for Claude in November 2024
OpenAI added agent SDK support recently
Microsoft also added support in various forms
For AI apps in Copilot studio
For their open-source projects like playwright. Playright can perform browser automation and will be able to act like operator
SDKs from popular languages like typescript, python, Java by spring, kotlin by JetBrains, C# by Microsoft.
The ecosystem has exploded for official and community-based MCP systems. See catalogs at github, MCP Servers and glama.
In this blog, I’ll provide technical details about the protocol.
What is context?
The primary purpose of MCP is to provide context (data and actions) to models (large language models like chatgpt, claude). Models are tuned based on public data and later optimized for certain use-cases via fine-tuning. However models do not update based on newer knowledge or have access to proprietary or local data. Hence additional data aka context can be provided to a MCP to make it relevant for a wide range of tasks via MCP. By having an open-standard it is possible to mix and match implementations for building complex solutions.
Arstechnica explains this well in their article.
Base protocol and architecture
MCP is a stateful protocol for exchanging messages between clients and servers. This makes the systems more complex compared to a stateless protocol like REST or GraphQL.
The underlying messaging format is based on JSON-RPC v2.0 (Remote procedure calls using JSON format).
Request from client to server
{ "jsonrpc": "2.0",
"id": 1,
"method": "resources/read",
"params": { "uri": "https://en.wikipedia.org/wiki/JSON-RPC" }
}
Response from server to client
{ "jsonrpc": "2.0",
"id": 1,
"result": {
"contents": [ {
"uri": "...",
"mimeType": "...",
"text": "..."
} ]
}
}
There are three types of messages-
Requests: Client or server can initiate a request which is identified by an ID. It includes method and parameters.
Responses: Successful or error response for a request (with ID)
Notifications: One way messages without any request ID
Request/Responses are asynchronous and both client and server need to keep track of the session and requestId to match.
A typical interaction will be like
Host (app) initializing a client which initializes a server session. For a complex app that integrates with multiple services, there will be many client-server sessions at one time.
Discovering features (capability negotiation) like resources, tools etc
Performing certain AI related tasks for the lifetime of the host
Termination commands
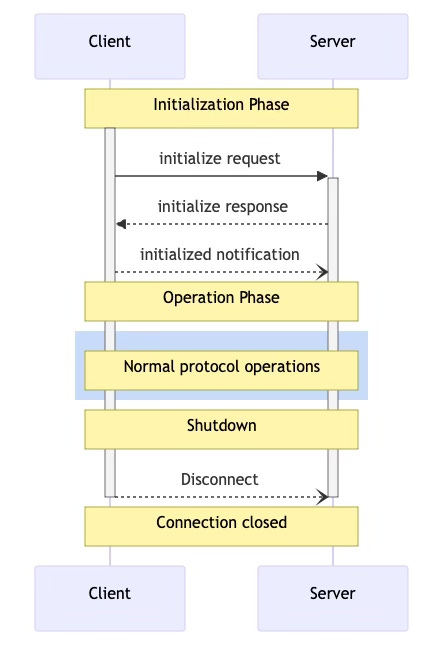
Server features
Servers expose the following optional primitives-
Resources
Read only resource endpoints typically exposed by servers via REST/GraphQL. These are meant to be invoked by the AI Application. Messages include
Listing resources for discoverability with support by pagination
Reading resources
Reading parameterized resources based on URI templates.
Notifications and subscriptions for changes.
Tools
Write, mutation or complex action endpoints. Functions or actions exposed to the LLM. These are typically API POST requests. These are Model controlled. Message examples include-
List tools with input required and description
Call tool with arguments. Result of a tool call can be content or resources.
Get notifications for changes in tools
Prompts
For AI applications, Interactive prompt templates are filled based on user choice. These are user controlled. Messages are
Discover available prompt templates with arguments and descriptions
Getting a prompt with arguments for the template which causes a response content.
Get notifications on prompt template changes.
Other server features include ping, completion and logging. I’ll skip advanced client features.
Composability and interop
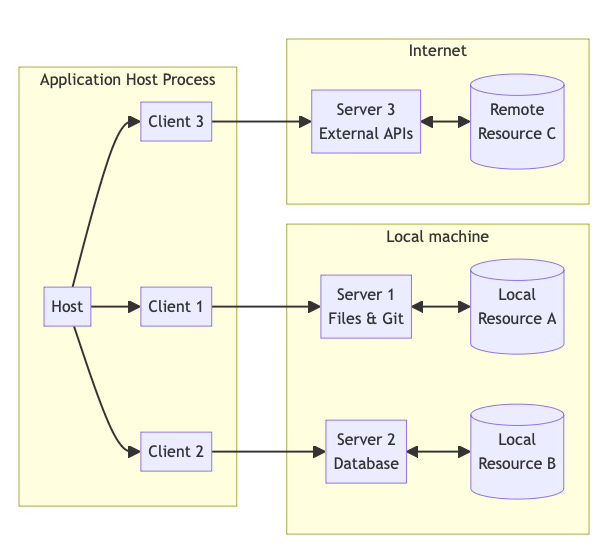
Another major design feature is composability.
Breadth - Each server can support limited functionality. Maybe only resources or tools or a combination of both. The client is supposed to discover the capability of a server dynamically. A host app can compose a solution by creating many client sessions with various servers.
Depth - A server can provide higher order API by aggregating capabilities of other servers. The Aggregate server can have auth and internally have client sessions to other downstream servers.
Thus it is possible for different tool, resource and LLM providers to provide smaller solutions which can then be aggregated for solving very complex problems.
Consider the use-case of asking your AI assistant to search for a recipe, order the items and buy them. This was the operator demo. It should be possible to do this by
tool like playwright as a browser driver
tool like brave search for internet search
LLMs like claude
any website for shopping and checkout (natively or via internet browsers)
Authorization
For remote server connectivity, authorization support was added in v2025-03-26 based on OAuth.
For direct client to server connections, OAuth 2.1 for public clients using PKCE (important for public clients (like mobile apps and Single Page Applications) where client secrets cannot be securely stored) is used. Third party auth flow is also supported for server based applications.
What’s next
MCP has prioritized getting a local version of the tooling out first based on standard I/O communication. This allows for completely local tools to be built. Examples of local protocol includes local files, and browsers. This has led to a bottom-up growth of adoption which is now forcing large players to also provide integrations and support. This allows for exciting tooling to be built for scenarios like home automation. Multi-language SDKs lower the bar on adoption.
However, the specification is still in fairly early days. There are going to be extensions for complex scenarios like aggregating servers, transforming data, streaming results, multi-modal results, sandboxing for security, and more.