Designing an extensible inventory system [tech]

I’ll go through a simplified high-level architecture design for a service in this post.
Problem statement
Build a service that can show the inventory of resources (cloud resources like compute, databases) within the organization. These should be mapped to teams, individual owners, and microservices that they own.
Teams (and individuals) continue to use established infrastructure tools built in-house to deploy to production. A service registry exists for use by the teams.
The external infrastructure providers have API’s that can be used to get the current state of the deployed state of the resources. There are many resource types with complex relationships between them and over time new ones get added.
The service should be able to automatically ingest resource and service information and provide a queryable API for consumers.
Functional requirements
MUST Provide a query API for the inventory system
MUST Automatically ingest infrastructure resource and service registry information
MUST Associate infrastructure to service registry data
MUST Design should be extensible for new resource types
MUST Automatically detect deleted resources
Non-Functional requirements
MUST Query APIs should return in $a00ms.
MUST Handle $b resource objects and relationships
MUST have 99.c% availability for the query APIs
MUST Detect new resources within $d hours
MUST clean up old resources within $e hours
Design
Thoughts
The data model needs to be fairly extensible since the resources that are stored in the system are disparate. There are a few common properties required for each resource like an id, type, and created/updated timestamps.
Relationships between resources are also disparate. A load balancer can have machines routed to. The load balancer itself has machines that are part of its internal implementation.
In the future, there will be new types of resources (say adoption of serverless?) and relationships as well.
Querying patterns can be varied. A service owner can be interested in starting from resources that are owned to dependent services or calling services. An infrastructure admin can look for all queues with some tags.
Fetching information from the infrastructure provider is incremental. Different APIs exist for different resource types and those have references to other resources (owned ie children or associated).
The query path for consumers is similar to a typical read-only REST service/
Processes for fetching data are stream or batch based and are not real-time.
Data model
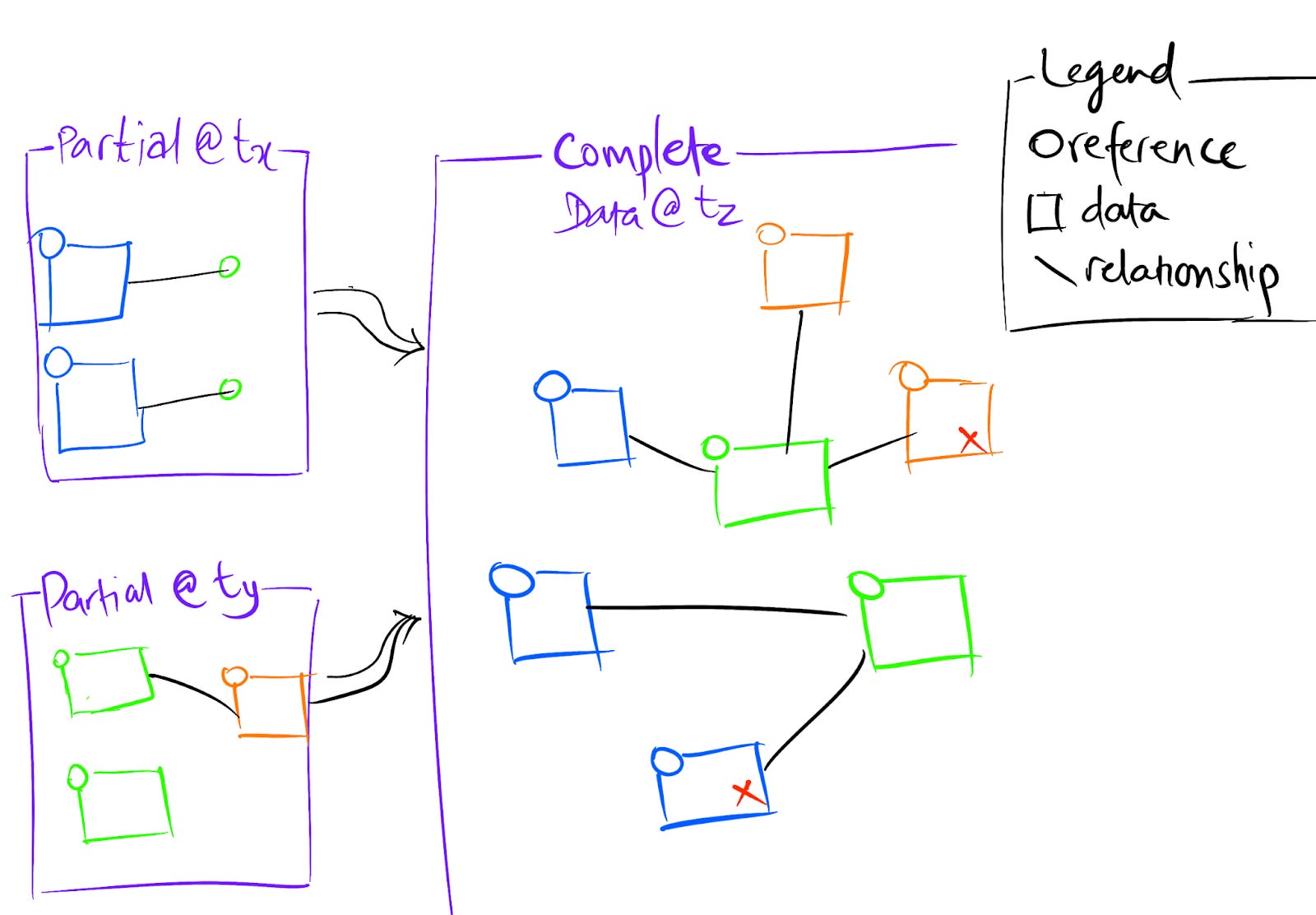
A Graph database will be used to store the data for the system. Graph databases use nodes and edges to store and query data. Dynamic nodes, edges and properties (or attributes) satisfy the requirement for extensibility in managing dynamic resource types.
Each resource mapped to a node in the graph. A small number of attributes are required like id, type, creationTime, updateTime, syncTime. Other attributes are dependent on the type of the resource.
Relationships between resource nodes are stored as relationship nodes in the graph. Edges are created between resource nodes and relationship nodes. A relationship node itself has attributes like references to the resources that it connects, id, type, timestamps and other dynamic attributes as needed.
Identifiers along with the type of resource need to be stable for the system. Since resource information is synced from various systems, all of them should use the same references.
At various times, different source systems will provide a partial graph state (some resources and/or relationships) which will be merged into the current state.
Based on querying the current nodes by syncTime, stale data can be deleted.
SPARQL is used to perform operations on the graph database. SPARQL is a W3C standard and provides constructs for efficient traversal, querying and updating. This satisfies extensible querying patterns by clients.
Service design
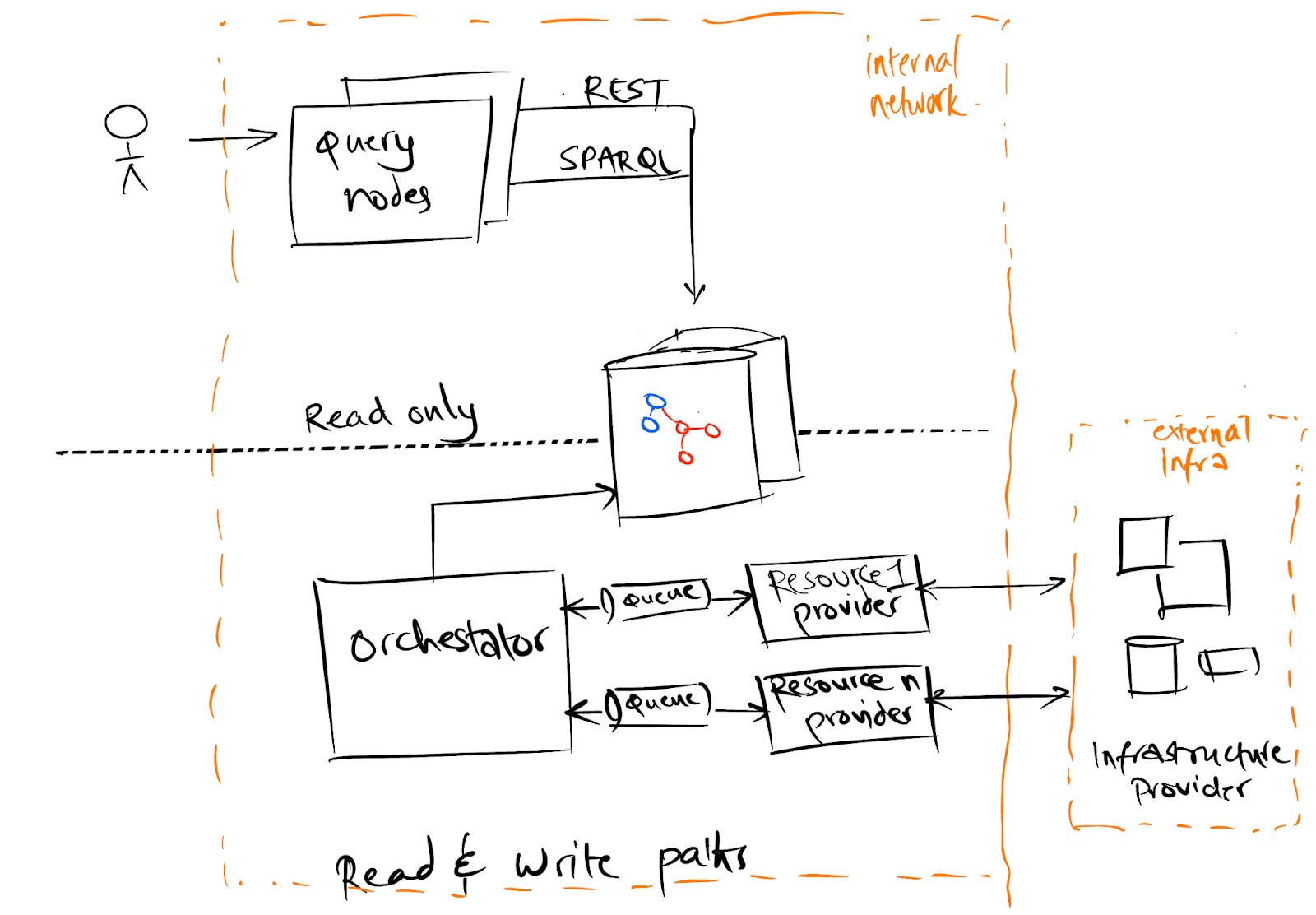
Read sub-systems
Multiple query endpoints (Query nodes in the diagram) will be available for consumers to fetch data from the system
Query endpoints will have read-only access to the internal graph database. Based on scale, these can be read-only replicas based on the primary database.
The query endpoints are stateless nodes
Query endpoints perform authentication checks
Query endpoints will expose REST and SPARQL APIs for extensible query requirements.
Endpoints (and read replicas) can be deployed in multiple locations for higher availability and performance.
Clients will need to handle partial data, or stale data. Only certain required attributes will always be present. Other attributes are based on the resource type.
Write sub-systems
Based on the API’s available to fetch information from various sources (infrastructure providers), different “Resource Providers”(RP) will be created.
Each RP will fetch a partial graph of some resources from a source.
A RP can be push or pull based depending on the source.
The RP will normalize the data into the common graph model and send data to the processing queue
A RP is an independent system which isolated scale and failure models.
RP location is preferably the same as the orchestrator.
Based on the queue message size, the RP will need to implement throttling
Based on the source system, the RP will need to implement throttling
Orchestrator (O) pulls data from different resource providers and merges into the graph database
Data is pulled from queues (ie RPs) for persistence
Basic validation checks are made on the data before persistence
Persistence from providers follows upsert semantics (ie insert or update).
O should perform periodic tasks to purge out stale data based on the time-to-live of the resource type.
O can be single location and have multiple nodes based on the write throughput of the primary database.
O will need to scale based on the schedule of the RPs added.
Out of scope
Querying state over time rather than only current known state.
Federated graph databases to support higher scale write throughput.
Closing thoughts
All data models can be expressed generically as a graph, but this was one instance where the extensibility and query requirements made it practical.
Thinking about partial data implications was challenging. My past work on clojure inspired me to go with this approach. Clojure is a dynamic language and they think of data in a less strict form which helped me.
Working with SPARQL was refreshing. There were some quirks that we learnt along the way!